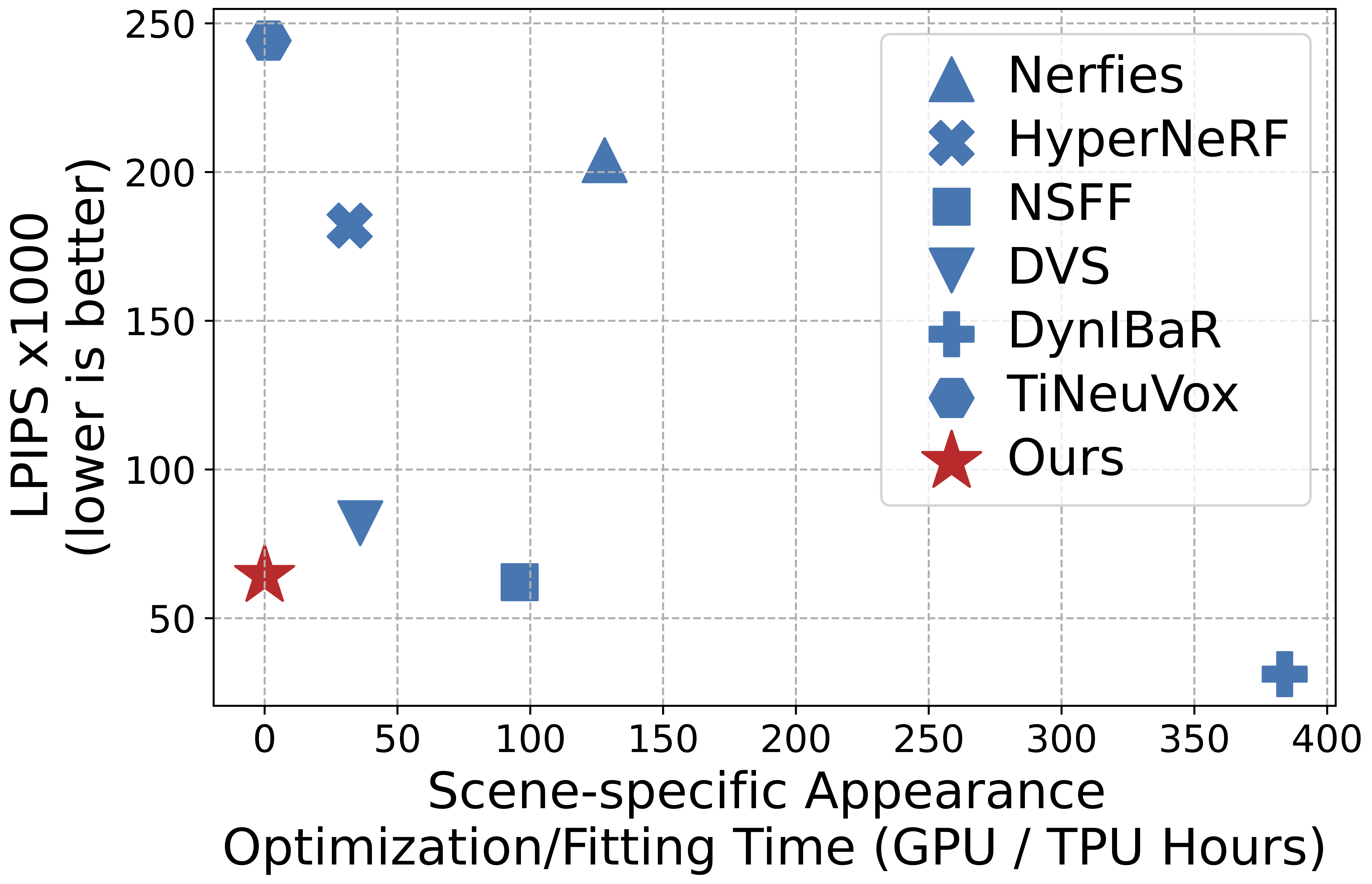
Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. We cannot help but ask a natural question:
"Is generalized dynamic novel view synthesis from monocular videos possible today?"
To answer this question, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find
"A pseudo-generalized approach, i.e., no scene-specific appearance optimization, is possible, but geometrically and temporally consistent depth estimates are needed."
To clarify
- We use the word pseudo due to the required scene-specific consistent depth optimization, which has already been utilized in many scene-specific approaches and can be replaced with depth from physical sensors, e.g., an iPhone LiDAR;
- We call it generalized because of no need for costly scene-specific appearance fitting.
Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.